
Zur
Architektur des semantischen Raumes bei der Diagnosecodierung
Straub HR, Demarmels MA, Frei N, Mosimann H
Projektgruppe für semantische Analysen in der Medizin, Zürich,
straub@meditext.ch
1.
Einleitung
Im Gesundheitswesen liegt ein entscheidender Teil der Daten in Form von Texten vor. Diese Texte sind zwar sehr aussagekräftig, weil sie aber nicht in einer standardisierten und wohlstrukturierten Form vorliegen, sind sie statistisch schlecht auswertbar. Dem Mangel kann prinzipiell auf zwei Weisen abgeholfen werden, entweder durch das Erzwingen einer standardisierten Sprache a priori (kaum durchsetzbar) oder dann durch die Interpretation der heterogenen Sprache a posteriori. Die Codierung von Diagnosen stellt einen solchen Versuch der nachträglichen Strukturierung dar, in der Hoffnung, damit Transparenz über die Vorgänge in unserem Gesundheitswesen zu erlangen.
2. Das semiotische Dreieck nach Ogden und Richards und
der semantische Raum
Ogden und Richards [1] unterscheiden in ihrer Arbeit über das semiotische Dreieck zwischen Symbolen, Gedanken und Objekten. Wenn wir codieren, dann bewegen wir uns von Symbolen (Worten) zu anderen Symbolen (Codes). Die Bewegung findet über Vorstellungen in unseren Gedanken statt. In diesen Vorstellungen sind die Bedeutungen der Worte und Codes enthalten und die Codierung besteht darin, die Bedeutungen miteinander zu vergleichen und den zur Bedeutung der Worte am besten passenden Code auszuwählen.
Vergleich und Auswahl finden im semantischen Raum der Begriffe statt. Dieser Raum unterscheidet sich vom uns gewohnten 3-dimensionalen Raum in vieler Hinsicht. Eine präzise Beschreibung des semantischen Raums ist für die Darstellung des Codiervorgangs notwendig und somit für die erfolgreiche automatisierte Diagnosecodierung eine Voraussetzung.
3.
Achsen und Werte im semantischen Raum
Eine Dimension im semantischen Raum kann als Achse angesehen werden. Sie enthält einen informatischen Freiheitsgrad. Die Achse entspricht einem Merkmal (z.B. Farbe) und ein Wert auf der Achse der Ausprägung des Merkmals (z.B. grün). Für die Beschreibung des Spiels der Werte (=Begriffe) und Achsen sind unterschiedliche Architekturen gebräuchlich..
4.
Die hierarchische (=monoaxiale) Architektur
Die einfachste Architektur, die Hierarchie, kennt nur eine Achse. Alle Werte bilden sich auf diese Achse ab. Obwohl in Abb. 2 die Begriffe zweidimensional angeordnet sind, ändert sich die Information qualitativ nur in der einen, nämlich in der horizontalen Richtung. In der Vertikalen ändert sich dagegen Präzision und Geltungsbereich des jeweiligen Begriffs, d.h. die Granularität der Information.

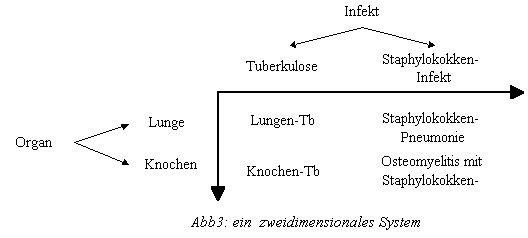
Eindimensionale, monohierarchische Systeme stehen nicht nur am Ursprung der europäischen Systematik, nämlich bei Platon und Aristoteles. Dank ihrer Einfachheit sind sie auch ideal für den Einsatz in Archiven und Computersystemen. Probleme entstehen durch die sogenannte "kombinatorische Katastrophe": Wenn ich m Ausprägungen des einen Merkmals mit n Ausprägungen eines zweiten kombiniere - z.B. 100 Infektionskeime mit 10 Organen - dann erhalte ich m*n Kombinationen - im Beispiel 1000 Krankheiten. Die Zahl der Kombinationen ist ein Produkt und steigt entsprechend viel stärker an als die Summe der Einzelausprägungen. Eine monohierarchische Systematik erfordert deshalb auf dem feingranulären Layer eine unverhältnismässig hohe Anzahl von Blättern. Die ICD-10 braucht zur Darstellung einer Information von nicht ganz 14 Bit über 14'000 Blätter (4-Steller). Bei gröberer Granularität entstehen zudem Überschneidungen - wie z.B. zwischen "Lungenkrankheit" und "Tuberkulose". Der eine Begriff spezifiziert das Organ, der andere den Keim. Korrekt auseinandernehmen und darstellen lassen sich die begrifflichen Inhalte nur in einem semantischen Raum, welcher die beiden Merkmale getrennt behandelt (siehe Abb. 3).
5.
Die multidimensionale Architektur
Die mehrdimensionale (=multiaxiale) Architektur besitzt als kombinierende (=komposite) Architektur die Potenz, der "kombinatorischen Katastrophe" zu begegnen:
Mehrdimensionale Architekturen verfügen über mehrere unabhängige Achsen. Wenn wir alle Achsen in einem Zentrum sich schneiden lassen, dann spannen sie einen mehrdimensionalen Raum auf und ein Punkt in diesem Raum wird durch je einen Wert auf jeder Achse definiert. Als Beispiel einer mehrdimensionalen Architektur verfügt die SNOMED in der Version 2 über sieben und in der Version 3 über zwölf Achsen. Der Anstieg der Achsenzahl ist typisch, da mit der Verfeinerung der Systematik immer mehr eigenständige Merkmale getrennt eine eigene Dimension (einen eigenen Freiheitsgrad) erhalten. Zu viele Achsen aber sind unübersichtlich. Auch sind für einen konkreten Fall dann nicht mehr auf allen Achsen Werte sinnvoll, d.h. es entstehen sinnlose Kombinationen.
6.
Die multifokale Architektur
Diese
Nachteile der einfachen multidimensionalen Architektur überwindet die
multifokale Architektur, welche mehrere
explizite Verzweigungspunkte (Foci) besitzt, an denen von einem beliebigen
Punkt einer bestehenden Achse neue Achsen ausgehen (siehe Abb.4, dort ist z.B.
Fraktur ein Fokus). Multifokale Architekturen lassen sich mit relationalen
Datenbanken, den Datenstrukturen der OOP, der GRAIL des GALEN Projektes [2] und
mit J.F. Sowas Conceptual Graphs [3] darstellen.

7. Die multipunktuelle Architektur
Die konkrete Arbeit bei der Wissensrepräsentation in der Medizin zeigt jedoch, dass Probleme vor allem bei der Darstellung von Multimorbidität und zusammengesetzten Syndromen auftreten, d.h. immer bei summierenden Begriffen. Dabei wird es nötig, auf der selben Achse mehrere Punkte gleichzeitig aktiv zu halten (z.B. Ulna und Radius auf der Achse Knochen bei der Vorderarmfraktur). Auch im Raum, der durch die Achsen aufgespannt wird, sind dabei mehrere Raumpunkte für die gleiche Entität wirksam. Eine solche multipunktuelle Wissensrepräsentation muss formal geregelt werden. Der semantische Raum bleibt zwar der gleiche wie bei der multifokalen Architektur, doch auf einer Achse können nun mehrere Punkte gleichzeitig einen einzigen Begriff ausmachen. Ein formales Element [5] addiert dabei die Summe (whole) aus den Summandenpunkten (parts).
8. Die Rolle der Architekturen bei der Codierung
Der semantische Raum ist entscheidend für die Darstellung der Begrifflichkeit, also der Bedeutung von Worten und Codes. Erst mit Architekturen der 4. Generation (multipunktuell) können medizinische Begriffe widerspruchsfrei systematisiert und verglichen werden. Mit der multipunktuellen Darstellung gelingt es, die gesamte Information der textlichen Diagnosebezeichnung festzuhalten, und zwar in einer Form, welche für den Computer einfach weiterverarbeitbar ist.

Durch die Erstellung des internen Datenformates (=semantische Darstellung, Abb.5) werden die heterogenen Freitexte datawarehouse-gängig. Dank des hohen Informationsgehalts der primären semantischen Darstellung, ist es möglich, sekundär und automatisiert aus dieser Darstellung heraus für verschiedene Zwecke und Codewerke zu gruppieren [4,5].
Referenzen:
(1) Ogden C.K., Richards I.A.: The Meaning of Meaning. Orlando: Harcourt
1989
(2) Rector A. et al: A Terminology Server for Medical
Language and Medical Information Systems. Methods of Information in Medicine,
34, 1995: S 147-157
(4)
Straub H.R, Mosimann H: Codierung als Interpretationsvorgang. Schweizerische
Medizinische Wochenschrift, 129, 1999: Suppl
105/II, S 27S
(5)
Straub H.R.: Das interpretierende System - Wortverständnis und
Begriffsrepräsentation in Mensch und Maschine, mit einem Beispiel zur
Diagnosecodierung.. Wolfertswil,
CH: Z/I/M-Verlag 2001
Dieser Text ist Teil des Buchs: Das interpretierende System